What Happens After AI Writes the Code
You wrote some code with Claude Code, opened a Pull Request, went into a couple of hours of meetings, and what do you see when you’re back? The CI failed.
The code you pushed looked right at first glance, and the unit tests had passed. But now you’re staring at a stack trace that points to a field that doesn’t exist on your queue messages, or an environment variable the service is calling by the wrong name, or a database column that was renamed last week.
These are the kinds of bugs AI coding agents are more prone to introducing, and simply reading the code or testing it in isolation doesn’t allow you to catch them. In this blog we’re going to be talking about why this happens and what are some ways to prevent this by giving AI agents safe environments to test in.
The assumption gap
When an AI agent writes code, it works from what it can see: the files in your repo, the context you gave it, maybe some docs. What it can’t see is your actual environment, the exact format of messages on your queue, the names of your secrets, the response structure of the internal API three services downstream, the current state of your database schema.
So it guesses. The guesses are usually reasonable, but reasonable isn’t the same as correct, and incorrect in this case is invisible until the code runs against the real thing. I’d like to name these types of bugs as “assumption bugs.” The code is correct given a set of premises about the environment that turn out not to be true.
Human engineers make the same mistakes, but with two key differences. First, a human working on a service has usually run it, seen its logs, made requests against it. They have ambient environmental knowledge built up over time. Second, and more importantly, when a human does make an assumption, they know they made one. A developer who’s unsure how a queue message is structured will go and check or at least flag it mentally as something to verify.
An AI agent has neither the environmental knowledge nor the awareness that it’s guessing. It writes assumptions into the code with the same confidence as everything else. And even if it’s worked with that environment before, its context window leads it to forget certain things when the app gets complex. The result is code that looks authoritative but is built on premises it never verified.
Why you always find out late
The CI failure which caught the errors in the AI-generated code, didn’t have to happen hours later. It happened hours later because of how most current dev workflows are set up.
Here’s what the loop looks like today: the AI generates code, it looks plausible, you push it, a container image builds (10–15 minutes on a good day), you wait for access to staging, CI deploys to staging, and then it fails when run against real dependencies in a real environment the AI has never had access to. Now you have to go back, figure out what assumption the AI made, re-explain the context, prompt again, and run the whole cycle over.
The gap between “AI wrote the code” and “the bug is found” is where the time goes. And the longer that gap, the harder it is to close because by the time you’re reading the stack trace, you’ve already moved on mentally from the context you had when you were prompting.
But what if your AI agent could run the code against real dependencies before the push and not after? If the agent can start the service locally and immediately see how it behaves against the actual queue, the actual database, the actual downstream APIs, assumption bugs surface in seconds. The AI can observe the real response, adjust, and try again on its own.
That’s a different kind of workflow. Not generate → push → wait → fail → iterate. Generate → run → observe → fix → push with confidence.
Giving the agent an environment
We call this type of workflow “remocal development” — your locally running service connects to your remote staging Kubernetes cluster in real time without any container builds or deployments. The service runs on your machine, but it receives real incoming traffic from the cluster and talks to real dependencies like databases, queues, and other services in the cluster.
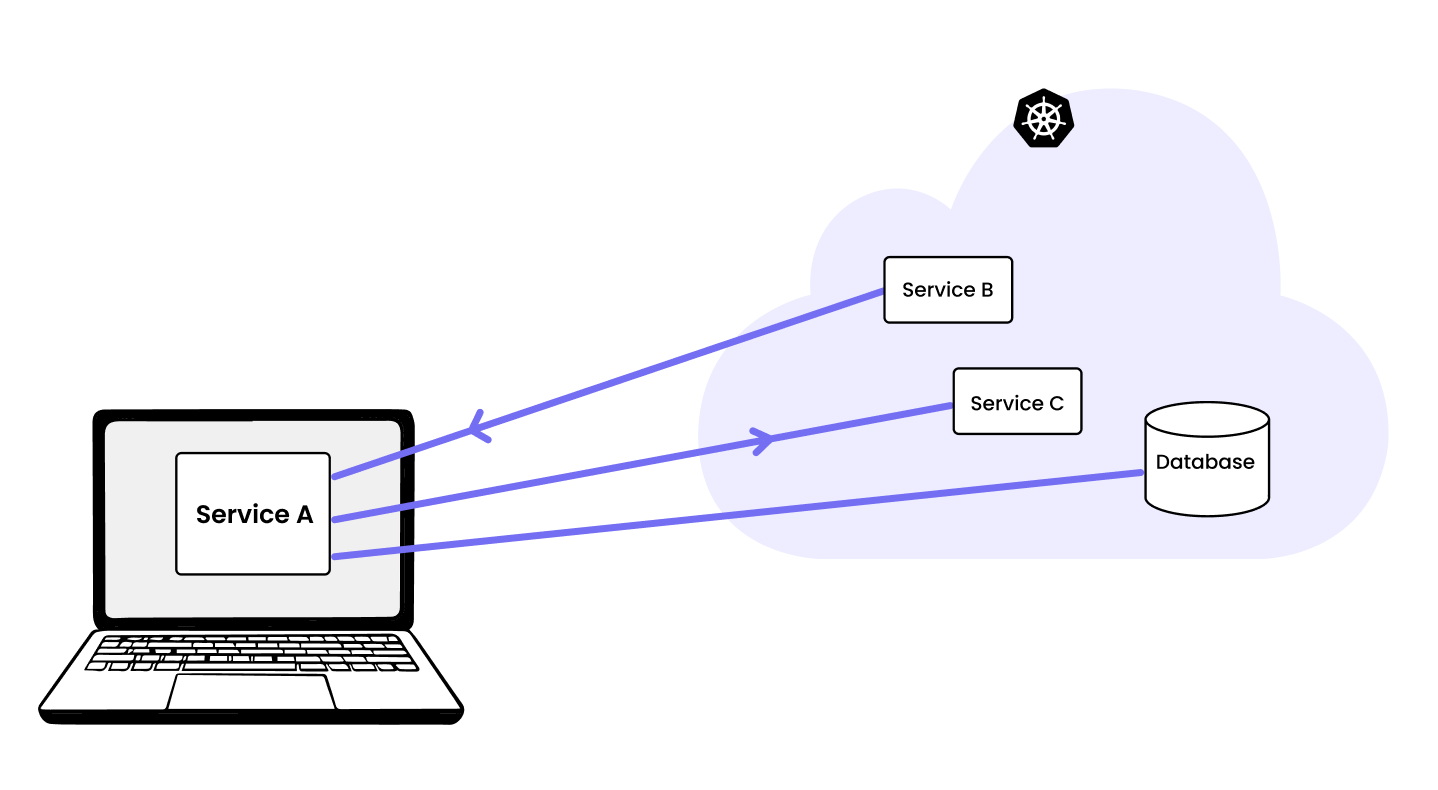
How remocal development works
In practice, the workflow changes like this: after the AI generates the code, instead of pushing it, it runs the service locally with a remocal development solution like mirrord. The assumption bugs that would have shown up in CI two hours later show up now, immediately, with full context still fresh. The AI can observe the real failure, adjust, and try again in seconds. By the time you push, the code has already run against the real environment.
Here’s a demo: we gave Claude Code access to mirrord and it spun up a team of agents working in parallel against a shared Kubernetes cluster which iterated on their own code by testing it:
What about shared staging?
The natural concern is that running AI-generated code against a shared staging cluster is risky because a bad assumption on the AI’s part could break the environment for everyone. mirrord handles this with a suite of features including HTTP traffic filtering, database branching, queue splitting and mirrord Policies. You can check out our docs to learn more about each of these. We already have 1000+ engineers at companies like monday.com, zooplus, and SurveyMonkey doing remocal development against a single shared staging environment using mirrord. You can read about how they use mirrord here.
What changes
With this workflow, you don’t come back from meetings to a failed CI. The agent already ran the code against real dependencies before the push. It already saw the wrong field name, the missing env var, the stale schema, and fixed them. By the time CI runs, that class of bug is gone.
And because the environment is shared and controlled, it scales, and you don’t need a separate environment for every agent. Multiple agents can test simultaneously against the same cluster without breaking each other’s work. Platform teams can set guardrails on what agents are allowed to touch. The whole thing becomes something you can actually let run on its own, rather than something you have to watch.
That’s what AI-driven development looks like when the environment problem is solved. It’s not faster code generation that’ll allow you to ship faster but a tighter loop between code getting generated and knowing it works.
