Auto-Verifying Your AI-SRE’s Fixes (Part II): HolmesGPT End-to-End on a Real Cluster
Part II of two. See Part I for the recipe.
In Part I we’ve discussed how you can plug mirrord into your AI-SRE so it can autonomously test its fix in the real cluster. In this post, we’ll show this running end-to-end on a real Kubernetes cluster against HolmesGPT, the only OSS AI-SRE we found that is self-hostable. We planted two bugs to test both possible verdicts: PASS when the patched run clears the alert’s SLO without any regressions, REJECT when it doesn’t (the patched run still violates the alert’s SLO, or cleared the SLO but added a regression).
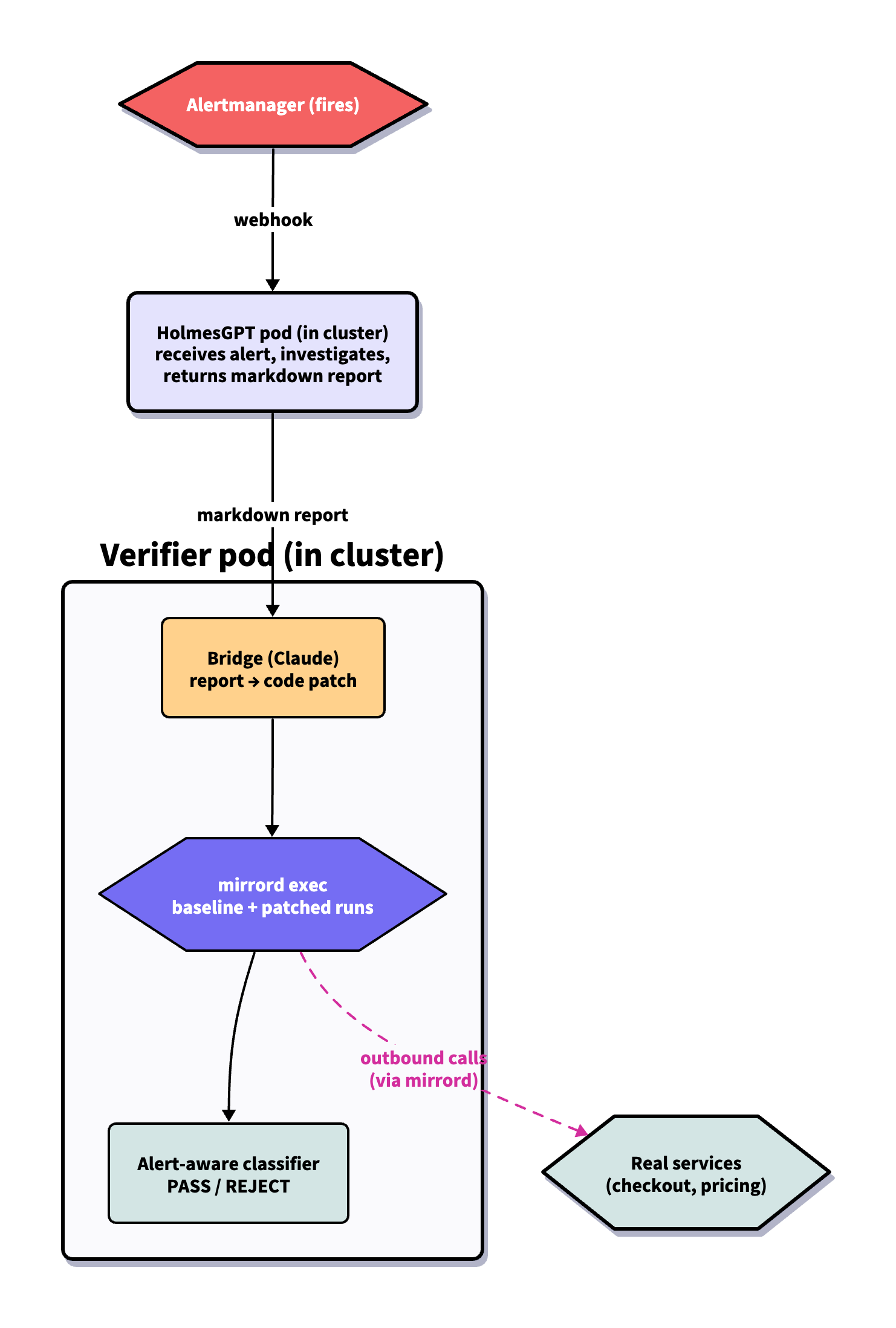
Flow: HolmesGPT investigates an alert and returns a markdown report. A small Claude wrapper turns the report into a code patch. The verifier runs that patch under mirrord exec, compares against an unpatched baseline, and returns a verdict tied to the alert’s actual SLO.
What’s HolmesGPT? A prebuilt LLM-backed agent tailored for on-call work: it can run
kubectlcommands, fetch logs from the cluster, and read the runbooks you’ve already written (in Notion, Confluence, or markdown files) to ground its investigation.
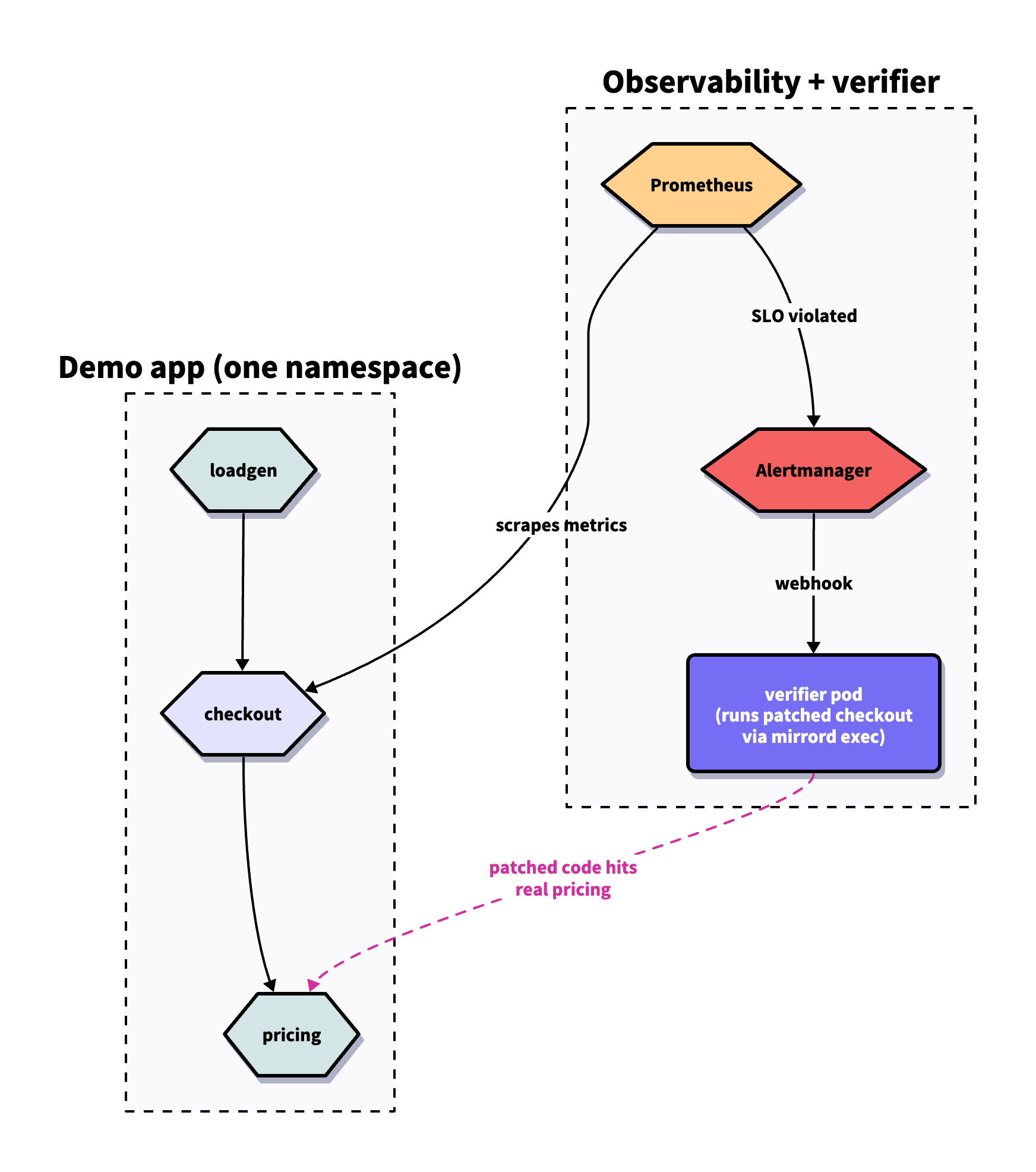
The demo cluster
A Python service called checkout handles HTTP requests; on each request it calls a pricing service for the item price. A loadgen pod sends requests to checkout continuously to keep the system warm. Prometheus scrapes checkout’s metrics and Alertmanager fires when SLOs are violated. Everything sits in one namespace.
HolmesGPT runs as a pod in the cluster, subscribed to Alertmanager. When an alert fires, HolmesGPT investigates and hands its markdown report off to a separate verifier pod. The verifier runs the bridge (the Claude call that turns the report into a code patch), then uses mirrord exec to run the patched code inside the verifier pod with deploy/checkout’s network identity, env, and mounts. When the patched copy calls pricing, it hits the real pricing pod.
Scenario 1: error-rate alert (PASS)
A recent change introduced a request format checkout() doesn’t handle: every request for an item_id ending in -3 raises ValueError and returns 500. Loadgen sends a mix; ~10% of requests fail. A Prometheus rule fires CheckoutErrorRateHigh once the error rate climbs over 5%.
HolmesGPT Investigates
This is the call HolmesGPT runs in-cluster when Alertmanager fires:
holmes investigate alertmanager \
--alertmanager-url http://localhost:9093 \
--alertmanager-alertname CheckoutErrorRateHigh \
--model 'anthropic/claude-sonnet-4-20250514'
HolmesGPT investigated for ~30 seconds (pulled pod descriptions, fetched logs, walked the service config) and concluded:
Root Cause: Application logic error causing 500 responses for specific item (item-3)
Error Details: Error rate: 20.09% (above 5% SLO). Specific error:
ValueError: unsupported catalog shape for item_id=item-3. Pattern: repeated failures for item-3 checkout requests returning HTTP 500.Remediation: Fix application code to handle item-3 catalog shape or add proper validation.
Clean diagnosis: HolmesGPT pulled the exception out of the logs and attributed it correctly.
Bridge to a code patch. HolmesGPT outputs a markdown report. The bridging step is a small Claude call running in the verifier pod (~80 lines around the Anthropic SDK) that takes the report plus the service’s source and returns a code patch. We asked it to faithfully implement HolmesGPT’s recommendation: handle the item-3 case (Claude chose to return zero) rather than raising. Claude produced the minimal edit to checkout.py.
Verify. Two runs (baseline and patched), 100 requests each. The verifier compares the alert’s SLO condition against the patched run, plus a regression watchlist on the other signals. The “baseline” here is the verifier’s own load test on the unpatched code, same load and same downstream as the patched run, not the live error rate HolmesGPT observed. That’s why the number below differs from the 20.09% in HolmesGPT’s report.
SLO under verification: error_rate > 5% (alert fires while this holds)
| Baseline | Patched | SLO threshold | Status | |
|---|---|---|---|---|
| Error rate | 10.00% | 0.00% | 5.00% | ✅ satisfies |
Regression watchlist:
| Signal | Baseline | Patched | Change |
|---|---|---|---|
| p50 latency (ms) | 469.2 | 470.5 | +0.3% |
| p99 latency (ms) | 505.7 | 531.8 | +5.2% |
Verdict: PASS. Alert condition error_rate > 5% no longer satisfied (10% → 0%). Regression watchlist clean.
Scenario 2: latency alert (REJECT)
The error-rate bug was easy: a literal exception in the logs with an obvious fix. What does the loop look like for a less log-visible bug? We swapped in the second planted defect: fetch_price() has no client-side timeout, and pricing has a long tail: 1 in 10 calls takes ~1.5s. p99 drifts to ~2 seconds, well above the 300ms SLO. CheckoutP99High fires.
Ask HolmesGPT:
holmes investigate alertmanager \
--alertmanager-url http://localhost:9093 \
--alertmanager-alertname CheckoutP99High \
--model 'anthropic/claude-sonnet-4-20250514'
Root Cause Analysis: Latency caused by synchronous dependency calls (each checkout request triggers pricing API calls), no apparent caching, potential bottleneck in pricing service.
Recommendations:
- Implement caching for pricing data to reduce API calls
- Add async processing for non-critical pricing lookups
- Monitor pricing service performance and scaling
- Consider request batching to pricing service
Caching is a reasonable optimization. It’s also generally a good idea. The question is whether it resolves this specific alert.
Bridge: Of the four recommendations, only caching is a single code change; the others are runtime tuning or architectural refactors. Claude implemented it as an in-memory TTL cache around fetch_price().
Verify.
SLO under verification: p99 latency (ms) > 300
| Baseline | Patched | SLO threshold | Status | |
|---|---|---|---|---|
| p99 latency (ms) | 2162.5 | 2010.3 | 300.0 | ❌ violates |
Regression watchlist:
| Signal | Baseline | Patched | Change |
|---|---|---|---|
| p50 latency (ms) | 529.8 | 0.9 | −99.8% |
| Error rate | 0.00% | 0.00% | no change |
Verdict: REJECT. Alert would still be firing post-merge. SLO p99_ms > 300.0 (baseline 2162, patched 2010).
p50 dropped 99.8% (cache hits return instantly), but the 99th-percentile request is still a cache miss hitting the 1.5s tail. The alert-aware classifier says the thing the on-call needs to hear: the alert that fired would still fire on this code; SLO threshold 300ms; patched value 2010ms.
The fix HolmesGPT didn’t propose: a short client-side timeout on fetch_price() to fail-fast under the SLO instead of waiting out the 1.5s tail. We re-ran the bridge with a hand-crafted patch doing that; verifier returned PASS at patched p99 ~330ms. The point isn’t that HolmesGPT missed the right fix, it’s that the verifier surfaced the gap before the wrong patch shipped.
What the two scenarios show
The loop closes against a real OSS AI-SRE you can install yourself. HolmesGPT investigates, the bridge turns its report into a patch, mirrord runs it against the live cluster, the classifier returns a verdict tied to the actual alert.
PASS and REJECT both have to be useful or the verifier becomes decorative. Scenario 1 signs off on a real fix. Scenario 2 stops one that looks good (p50 −99.8%) but doesn’t clear the alert.
Run it yourself
The sample checkout/pricing services, Prometheus rules, verifier code, and bridge script are small (~500 lines of Python plus the ~80-line bridge). The code lives at github.com/metalbear-co/holmes-mirrord-verifier. You’ll need the mirrord operator installed in your cluster.
Frequently asked questions
What are the alternatives to HolmesGPT?
mirrord exec verification loop before it reaches a human.What can an AI-SRE do, and what are its limits?
mirrord exec in the loop tests each candidate patch against the live cluster, so only fixes that clear the alert’s SLO reach a human.How is verifying a fix with mirrord different from using a staging environment?
mirrord exec runs the patched code with the target pod’s real network identity, environment, secrets, and mounts, hitting the same live downstreams, in seconds and without a deploy. Each run is its own process, so you can verify many candidate patches in parallel, which matters in a noisy incident where the AI proposes several fixes.If you haven’t read Part I yet, it has the recipe: the pattern, the verification code, and how to wire it into the AI-SRE you’re already running.
Have questions? Reach out at [email protected] or on our community Slack
