Introducing DB Branching in mirrord: Run Against a Shared Environment With a Personal, Isolated Database
mirrord lets developers work directly against a shared Kubernetes environment by running their local code as if it’s already deployed in the cluster. This means you can test your code with real traffic, configurations, and dependencies, without waiting for CI or staging deployments. But one part of this workflow has always been tricky to handle: databases.
Databases in shared environments can be tricky to work with. A migration or schema change gone wrong could impact other developers, so many devs avoid testing such changes in the shared environment. Instead, they rely on local setups for that.
We wanted to give developers a safe way to test schema changes and migrations without risking shared resources. That’s exactly why we built DB Branching.
What is DB Branching?
DB Branching in mirrord lets you create a temporary, isolated branch for your database that mirrors your main database but stays completely separate.
When you run your app with mirrord and turn on DB Branching, mirrord creates a database branch and automatically overrides your DB connection string. Your local service now connects to this new DB branch instead of the shared database in your cluster.
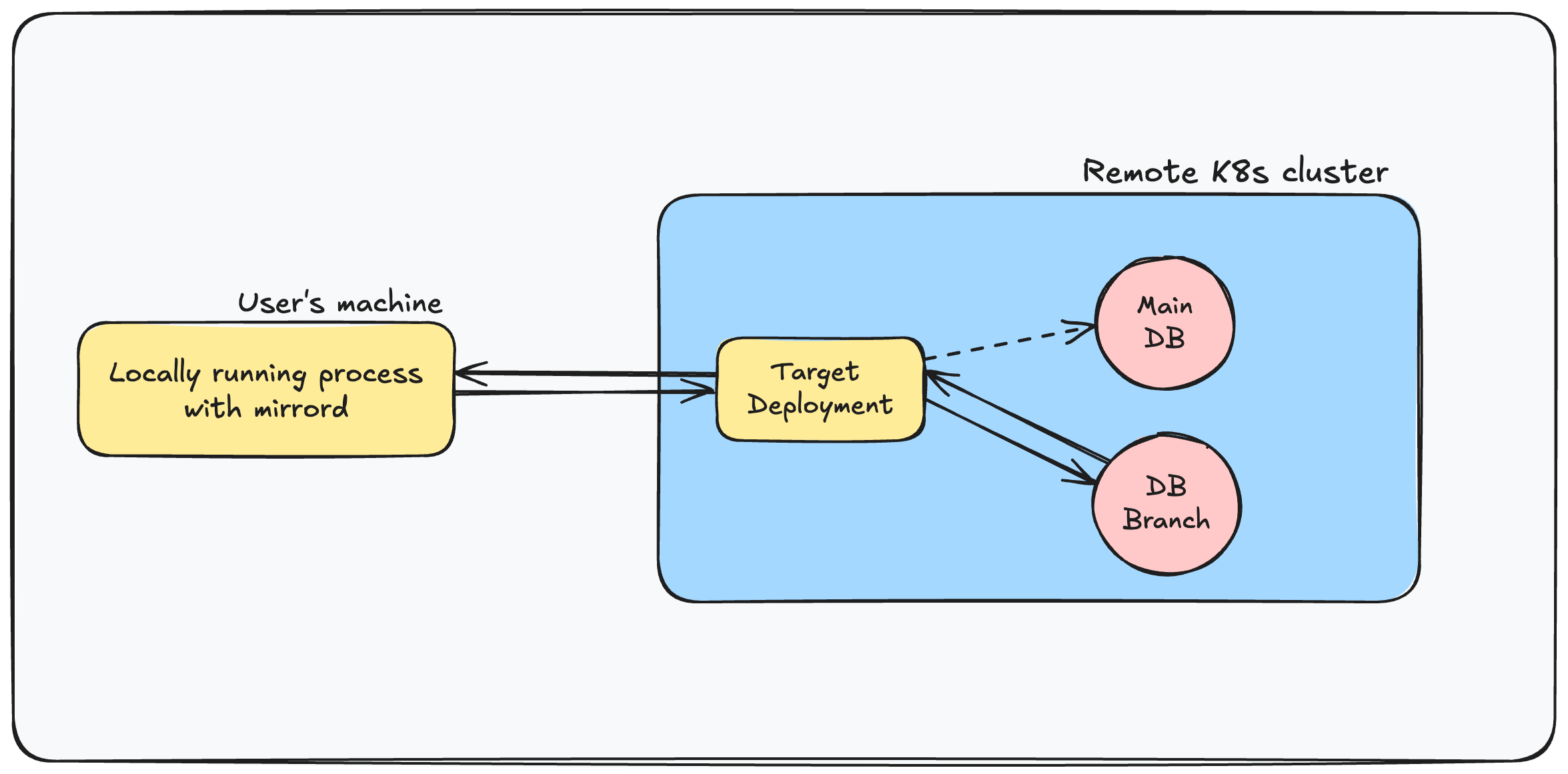
How DB Branching in mirrord works
This gives you a safe place to run migrations and try schema changes without risking the shared DB. You can even share the branch with a teammate so you can test together without juggling separate copies or syncing changes.
Now that we understand what the feature does, let’s see how to use it.
Step-by-step: Using DB Branching in mirrord
Let’s see how DB Branching works in practice, using a simple Go service that stores users in a MySQL database running on a local Kubernetes cluster. Note that we’re only using a local cluster here so that it’s easy to follow along. Ideally, you’ll want to use mirrord with a cluster that looks like your production environment, for example, a staging or testing cluster.
We’ll start by running the service with mirrord normally (without DB Branching), and then run it again with the feature enabled to safely test a schema change in isolation.
You can clone the sample app (which also includes the Kubernetes YAML files) from this repo.
Set up the Kubernetes cluster
I’ll use a local cluster with k3d, but you can use minikube, kind, or even a remote cluster if you prefer. If you’re using k3d, create a cluster with:
$ k3d cluster create db-branching-mirrord
Next, install the mirrord operator in your cluster. You can find detailed installation steps in our docs. In the cloned repo, the values.yaml file already has operator.mysqlBranching=true set to enable DB Branching.
$ cd db-branching-demo
$ helm repo add metalbear https://metalbear-co.github.io/charts
$ helm install -f values.yaml mirrord-operator metalbear/mirrord-operator
Then, deploy the users-api service and the MySQL database:
kubectl apply -f k8s.yaml
You can verify that everything is up and running using kubectl get pods,svc. You should see something like this:
NAME READY STATUS RESTARTS AGE
pod/mysql-854884d79b-9x5nk 1/1 Running 0 69s
pod/users-api-5c8579d7dd-v2jw9 1/1 Running 3 (41s ago) 69s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.43.0.1 <none> 443/TCP 2m14s
service/mysql ClusterIP 10.43.119.46 <none> 3306/TCP 69s
service/users-api ClusterIP 10.43.235.141 <none> 80/TCP 69s
Run the service with mirrord
Now let’s run our Go service locally through mirrord. I’ll use the mirrord extension for Cursor, but you can use the mirrord CLI or the mirrord extension for whatever code editor you prefer. If you’re new to using mirrord extensions, check out our IDE specific guides in the docs. When mirrord asks you to pick a target deployment, choose users-api:
Once it’s running, it should look something like this:
Adding a user to the main database
Let’s see how the app behaves when run with mirrord without DB Branching. Our sample Go service exposes an endpoint that lets you add a user by sending a POST request to /users?name=<name>.
When you run it locally through mirrord, it connects to the same MySQL database used by the users-api deployment in your cluster. mirrord automatically copies environment variables from that deployment, including DB_CONNECTION_URL which holds the connection string for the database, so you don’t need to set it manually.
With your local process running, send a request to add a user:
$ curl -X POST "http://localhost:8080/users?name=Alice"
ok: inserted "Alice" into users_db.users
$ curl -X GET "http://localhost:8080/users"
1 Alice
Now verify that the user was added to the MySQL database running in your cluster:
$ MYSQL_POD=$(kubectl get pod -l app=mysql -o jsonpath='{.items[0].metadata.name}')
$ kubectl exec -it $MYSQL_POD -- mysql -uroot -prootpassword -e "USE users_db; SELECT * FROM users;"
+----+-------+
| id | name |
+----+-------+
| 1 | Alice |
+----+-------+
What’s happening here is that mirrord tunnels outgoing traffic from your local process through target deployment in the cluster. To the MySQL database in the cluster, it appears as if the request is coming from the deployment in the cluster and not your locally running process. This lets your local code talk directly to the database running in Kubernetes, without needing to run MySQL (or other dependencies) locally, or opening up direct access from your local machine to the cluster. In practice, this also means that you can test your code using real data from your staging database.
But what if you need to make a major change, like updating the schema? Until you’ve tested it properly, you wouldn’t want to run it directly against the staging DB since it could easily break things for other developers. That’s exactly the kind of situation DB Branching was built for.
Enable DB Branching
Stop your locally running process, then enable DB Branching by updating your mirrord.json file. Add the following under feature:
"db_branches": [
{
"id": "branch-test-01",
"type": "mysql",
"version": "8.0",
"name": "users_db",
"ttl_secs": 300,
"connection": {
"url": {
"type": "env",
"variable": "DB_CONNECTION_URL"
}
}
}
]
This tells mirrord to create a temporary MySQL branch for the users_db database and automatically override your app’s DB_CONNECTION_URL to point to it.
You can read more about available configuration options for this feature in our docs.
Make a schema change
Next, let’s update our service to support adding an email field. Note that the startup code for main.go migrates the database to the latest schema. We’ll change it to add an email column, and change the request handler function to populate that column for new users.
First update the table schema by adding an email column when creating the users table:
- _, err = db.Exec(`CREATE TABLE IF NOT EXISTS users (
- id INT AUTO_INCREMENT PRIMARY KEY,
- name VARCHAR(255)
- )`)
+ _, err = db.Exec(`CREATE TABLE IF NOT EXISTS users (
+ id INT AUTO_INCREMENT PRIMARY KEY,
+ name VARCHAR(255),
+ email VARCHAR(255)
+ )`)
Then modify the /users handler to accept an additional email query parameter and insert it into the database:
case http.MethodPost:
name := r.URL.Query().Get("name")
+ email := r.URL.Query().Get("email")
if name == "" {
http.Error(w, "name required", http.StatusBadRequest)
return
}
- if _, err := db.Exec("INSERT INTO users(name) VALUES(?)", name); err != nil {
+ if _, err := db.Exec("INSERT INTO users(name, email) VALUES(?, ?)", name, email); err != nil {
http.Error(w, "insert failed: "+err.Error(), http.StatusInternalServerError)
return
}
Finally when fetching users, also return the email column:
case http.MethodGet:
- rows, err := db.Query("SELECT id, name FROM users ORDER BY id")
+ rows, err := db.Query("SELECT id, name, email FROM users ORDER BY id")
if err != nil {
http.Error(w, "select failed: "+err.Error(), http.StatusInternalServerError)
return
}
defer rows.Close()
w.Header().Set("Content-Type", "text/plain")
for rows.Next() {
var id int
- var name string
- _ = rows.Scan(&id, &name)
- fmt.Fprintf(w, "%d\t%s\n", id, name)
+ var name, email sql.NullString
+ _ = rows.Scan(&id, &name, &email)
+ fmt.Fprintf(w, "%d\t%s\t%s\n", id, name.String, email.String)
}
And that’s it. Now we’ve added email support and updated the API to handle it. Next, we’ll run the service again (this time with DB Branching ****enabled) to test the schema change safely in isolation.
Run again with mirrord (this time with DB Branching)
After the changes we made to our mirrord.json, when you run your service again with mirrord, it will automatically create a new database branch and connect to it instead of the original MySQL instance.
You should see a message showing that mirrord is creating the branch:
Once it’s done, let’s verify it by sending a request using the new schema:
curl -X POST "http://localhost:8080/users?name=Bob&[email protected]"
ok: inserted "Bob" into users_db.users
Check that your local app sees the new entry:
$ curl "http://localhost:8080/users"
1 Bob [email protected]
Notice that we don’t see Alice here because that record exists only in the original database, not in this new branch. You can confirm that mirrord created a new branch by listing your pods:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
mirrord-mysql-branch-db-pod-csrqr 1/1 Running 0 104s
mysql-854884d79b-b7jns 1/1 Running 0 10m
users-api-5c8579d7dd-2gz4x 1/1 Running 2 (10m ago) 10m
You’ll see an extra pod for the temporary MySQL branch. This is your isolated DB branch, and your local app is now connected to it instead of the shared database.
Finally, as a sanity check, make sure the main database (the one other developers might be using) is still untouched:
$ kubectl exec -it $MYSQL_POD -- mysql -uroot -prootpassword -e "USE users_db; SELECT * FROM users;"
+----+-------+
| id | name |
+----+-------+
| 1 | Alice |
+----+-------+
The main DB still has the original schema with Alice as the only record, while your branch contains Bob with the updated schema.
Try out DB Branching in mirrord!
Working with databases in a shared environment can be challenging. A small mistake or unexpected migration can affect others using the same setup, so developers tend to be cautious when testing changes there.
With DB Branching in mirrord, that stress is gone. Instead of testing against a shared database, you get an isolated, short-lived DB branch that mirrors your main DB and fits right into your existing mirrord workflow. Every time you run your app through mirrord, it automatically connects to this new branch instead of the real database.
In the example above, we started with a simple users table, made a schema change to add a new column, and verified that the update appeared only in our temporary branch, leaving the original MySQL untouched. Once you’ve tested and refined your changes in the branch, you can confidently promote them to your regular staging or CI workflow for final validation before merging to production. This approach lets you catch issues early while making sure your work doesn’t disrupt the shared environment for everyone.
Currently, DB Branching is available as part of our mirrord for Teams offering and supports MySQL databases. Support for more databases is on the way. If there’s a specific database you’d like us to prioritize, please open a GitHub issue and let us know.
If you want to give DB Branching a try or have questions, check out our docs for setup instructions, and join our community Slack to share feedback or ask questions!

