How To Prevent Token Burn Using mirrord With E2E Tests
The core of mirrord has always been the CLI, the IDE extension, and the operator. Increasingly, we’re putting more effort into the frontend side of the product, with new onboarding experiences and usage dashboards. We’ve been leaning on AI agents to assist with a lot of that frontend work, and it quickly became clear that if we didn’t run those changes through our established E2E tests, we risked breaking happy paths without knowing it. An agent that silently breaks a critical flow will keep building on top of the broken change, and when the failure finally surfaces, you’re stuck cycling through multiple rounds of fixes. That’s where the token burn comes from: not the initial mistake, but the compounding cost of every reasoning step the agent takes without realizing it’s already off track.
The conventional wisdom is that token waste is a prompt engineering problem: send less context, constrain your output format, start fresh conversations. That advice isn’t wrong, but it misses the bigger issue. For autonomous agents, the dominant source of waste isn’t how you talk to the model. It’s what happens when the model has no way to verify its own work.
E2E tests as agent guardrails
In cloud-native and microservice-based systems, the conditions in a real environment are vastly different from a local machine. Services depend on other microservices, databases, queues, and configuration that only exist inside the cluster. An agent working locally has no way to verify that its code actually works in that context. If it breaks something, it won’t know until a human reviews the PR or CI catches it. By then it’s built more code on top of the broken change, and every reasoning step along the way was another message in the conversation, each one carrying the full accumulated context. Tokens add up fast when the agent is circling a bug without knowing.
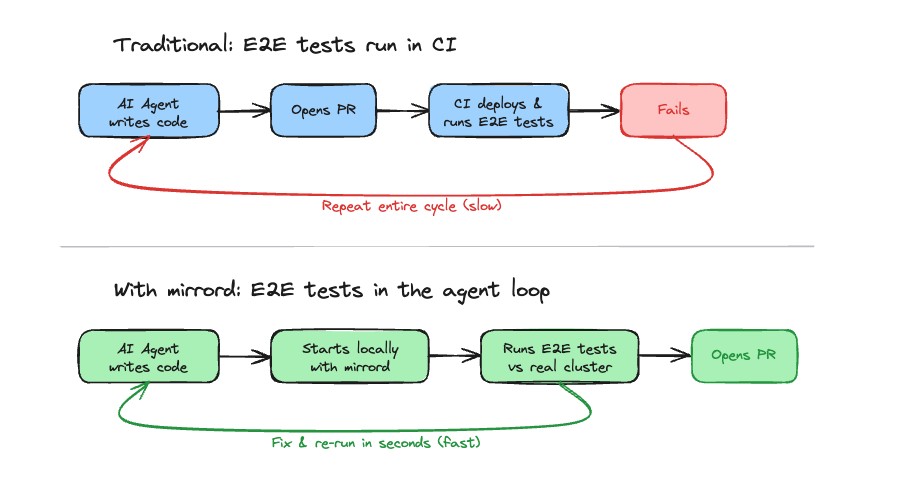
Developers have this same problem, and they avoid this by writing E2E tests around the critical flows, making sure each incremental change works on its own and in conjunction with the rest of the application. The same approach works for agents. You already have E2E tests that cover your critical paths. Instead of treating those as something that only runs in CI after the agent is done, you give the agent access to run them as part of its workflow. The agent makes a change, runs the tests, reads the pass/fail output, and either moves on or fixes the issue. One or two iterations instead of twenty. Nobody writes new tests for this - your existing suite acts as the guardrails. The agent can change code freely, but the critical flows your team already validated are protected.
But this only works if the tests run against real dependencies. If they hit mocks or a stripped-down local setup, the agent gets false confidence, passes tests that don’t reflect production behavior, and you’re back to the expensive debugging loop.
You could spin up a temporary environment for each agent session, but that’s slow and expensive at scale. You could try to run everything locally, but most services depend on databases, queues, and other services that are hard to replicate faithfully outside the cluster. What you really want is the speed of local execution with access to real cluster resources.
That’s what mirrord solves. mirrord lets a local process run in the context of a Kubernetes cluster without deploying to it. The agent changes code, starts the service locally with mirrord connected to the cluster, and runs E2E tests against real databases, real queues, and real downstream services. Pass/fail feedback comes back in seconds, without container builds or having to wait for CI pipelines to complete.
For the hands-on setup (mirrord configs, wrapper scripts, and how to write an AGENTS.md that teaches the agent the workflow), see our guide on using mirrord with AI agents.
What this looks like in practice
Say you have a service that handles orders, with payment confirmation and status tracking. You ask an agent to add discount logic that applies a percentage off before finalizing the order. Without guardrails, the agent makes the change, declares it done, and opens a PR. During review, you discover that the agent placed the discount logic after payment confirmation, modifying the total on an already-confirmed order and resetting the status back to pending. That kind of ordering bug only surfaces when running against the real payment service. That review-fix-review cycle burns your time and tokens.
With the E2E loop, the agent catches it on its own. It runs the tests against the real cluster, sees the failure (“expected status confirmed, got pending”), reads the error, realizes the discount logic is running after payment confirmation and resetting the order status, reorders the operations, and re-runs. The PR arrives with proof that the critical paths still work.
That’s one agent working on one service. But most teams don’t operate in isolation.
Scaling this across a team
Once one agent is testing against your staging cluster, the natural question is: what happens when your whole team is doing it at the same time? Multiple developers and agents all running local services against the same cluster could create collision risks: Traffic meant for one local instance hitting another, agents competing for queue messages, database writes interfering with each other. But this is exactly what mirrord handles best. It provides features like traffic filtering, queue splitting, and database branching so each agent session stays fully isolated from the others.
For a deeper look at how these features keep multiple agents and developers from colliding in a shared cluster, see Testing Is the New Bottleneck for AI-Driven Software Development.
Prompt optimization matters less than you think
Better prompts do help with token efficiency. Leading with a clear goal, constraining output format, and curating context. These are all good practices, but for autonomous agents, they’re secondary. An agent with great prompts and no test feedback will still burn tokens chasing integration bugs it can’t see. An agent with mediocre prompts and a working E2E loop will converge in a few iterations.
The highest-leverage thing you can do for token efficiency isn’t refining how you talk to the model. It’s giving the model a way to know whether its code actually works.
If you’re using AI agents with Kubernetes services, give mirrord a try. Let your agents run your existing E2E tests against real environments and see how quickly the token spend drops. Our guide on using mirrord with AI agents walks through the full setup, and if you’d like help getting it running for your team, we’re happy to chat.

