Enabling Self-Correcting AI Agents Through Autonomous Integration Testing
Recently, an article by Pedro Tavares titled “Writing Code Was Never the Bottleneck” reached #1 on Hacker News and /r/programming. In his article, Pedro argues that thanks to LLMs, the cost of generating new code is approaching zero, but the price of testing and trusting that code is higher than ever.
This is something I’ve felt myself as well and completely agree with. If you try to split an engineer’s work into different steps, the main ones are these:
- Design/Architecture
- Writing Code
- Writing Tests
- Reviewing Code
- Integrating
While Large Language Models (LLMs) have significantly streamlined tasks like writing boilerplate code, generating unit tests, and even automating parts of the code review process, they haven’t meaningfully solved one of the most persistent challenges in software engineering: integration.
In complex, distributed systems, especially microservice-based architectures, code (whether human- or AI-generated) almost never works on the first try. There are simply too many interdependent services, APIs, and configuration nuances. The only way to reliably surface these issues is through end-to-end integration testing.
This limitation is even more critical for autonomous AI coding agents. While they can rapidly produce large volumes of code, they lack the mechanisms to quickly and autonomously test their work across a live system. They are left with the same options as a human or AI-assisted code developer (unless they are using mirrord):
- Deploy to a shared staging environment and test there.
- Spin up a dedicated cloud environment for each agent to test in isolation.
But both of these approaches come with serious tradeoffs. Shared staging is slow and bottlenecked - only one agent can test at a time. Dedicated cloud environments solve that, but they’re slow to spin up and expensive to scale. If every agent needs its own environment, you quickly hit financial and operational limits on concurrency.
In effect, integration, the hardest part of building large systems, has now become the dominant bottleneck, as LLMs remove friction from earlier development stages. Solving integration testing for AI agents is the key to unlocking their full potential.
What if AI agents could handle integration testing on their own? If they could run end-to-end tests right after generating code, then use the feedback to fix the code they’ve written they’d be able to deliver working features end to end autonomously. And with mirrord, your AI agents don’t even have to wait for their turn. Instead of serially deploying to staging and testing one change at a time, any number of agents can test their code concurrently against the same environment. That means your AI agents can not only complete the full cycle from code generation to integration testing, but also do it in parallel, massively speeding up development.
Let me show you how this can be made possible by giving your AI agents access to mirrord.
What is mirrord?
mirrord is a tool we built to let developers run code in a production-like setting as soon as they write it, instead of having to go through builds and CI pipelines and deployments. mirrord does this by running your local code directly in the context of your Kubernetes cluster without deploying it to the cluster itself. Instead of replacing or modifying the remote service, mirrord mirrors cluster traffic and resources to your local machine, allowing you to test changes in real time. This not only allows developers to test in the cloud faster and earlier in the development cycle, but also enables multiple developers to test and iterate on their changes simultaneously, without interfering with each other or the live cluster state.
In today’s world of AI-assisted development, mirrord already lets developers test AI-generated code more effectively. In this post, we’re going a step further: instead of just assisting developers, we’re giving AI agents the autonomy to test and iterate on their own code, effectively closing the loop themselves. This unlocks a new level of speed and capability. We’ll walk through how this works using Claude Code, though any AI agent should be able to follow a similar approach. If you’re using tools like Cursor or Windsurf, check out our earlier blog post, which focuses on AI-assisted workflows, for specific guidance on using them with mirrord.
Teaching your AI agent to integration test
The first thing we need to do is teach our AI agent, Claude Code in this case, how to use mirrord. mirrord can be used as a standalone CLI or via IDE extensions. For this example, we’ll assume you have the mirrord CLI installed on your local machine and go with that approach. The first thing we start with is creating a CLAUDE.md file that shows Claude how to use mirrord to test our application:
# Running/Testing ip-visit-counter in staging before deploying - USE THIS INSTEAD OF DEPLOYING TO STAGING
To run ip-visit-counter in staging without deploying, you can use:
```
mirrord exec -f .mirrord/mirrord.json -- go run ip-visit-counter/main.go
```
Then you can access it via playground.metalbear.dev if you set header "X-PG-Tenant" to have value "Aviram". For example
`curl -H "X-PG-Tenant: Aviram" playground.metalbear.dev/count` will go to the local instance
In this example, we’re using a demo application we’ve built called the IP visit counter app. This app is deployed to a Kubernetes cluster and is available at the playground.metalbear.dev URL. When you send a request to that URL, the app responds back with the count of the number of times it has been sent a request from your IP. Behind the scenes, it stores and retrieves these counts from a Redis database running in the cluster. This is what the architecture of the app looks like:
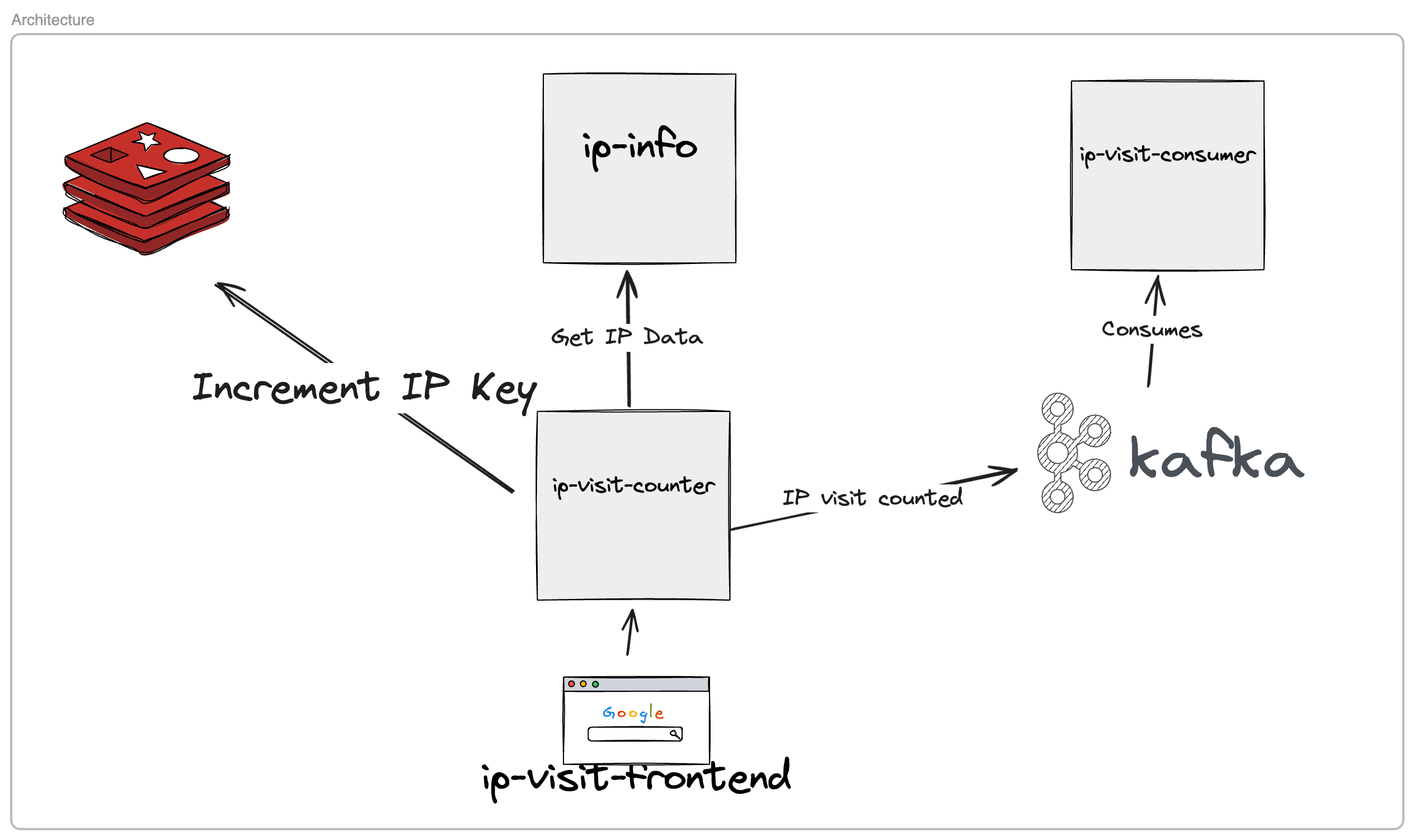
Architecture of the IP visit counter app
Our CLAUDE.md file instructs Claude Code to use the mirrord exec command for testing instead of running CI/CD pipelines that deploy the code change to staging and only then let us test it. The mirrord exec command will run our code locally but have mirrord mirror all the requests sent to the app URL to our locally running process. mirrord will also mirror any outgoing traffic from our local service and make it seem like it’s coming from the IP visit counter service’s pod in the cluster. This allows our local process to interact with other dependencies in the cluster that are not running locally, like other services and databases (Redis in this case). This way, Claude will be able to test our code as if it were running in the cluster without actually having to deploy it.
Once we’ve explained to Claude Code how to test our service, we can then ask it to add a feature to our application. This is the prompt we give it:
Modify the IP visit counter to return both the visit count and the total number of unique IPs saved in Redis. Run tests against staging.
And this is what the conversation history looks like:
╭───────────────────────────────────────────────────╮
│ ✻ Welcome to Claude Code! │
│ │
│ /help for help, /status for your current setup │
│ │
│ cwd: /Users/aviramhassan/Code/playground │
╰───────────────────────────────────────────────────╯
> Modify the IP visit counter to return both the visit count and the total number of unique IPs saved in Redis. Run tests against staging.
⏺ I'll help you modify the IP visit counter to return both the visit count and unique IP count, then test against staging.
⏺ Search(pattern: "ip-visit-counter/**/*.go")
⎿ Found 1 file (ctrl+r to expand)
⏺ Read(ip-visit-counter/main.go)
⎿ Read 298 lines (ctrl+r to expand)
⏺ Update(ip-visit-counter/main.go)
⎿ Updated ip-visit-counter/main.go with 9 additions and 1 removal
197 return
198 }
199
200 + // Get total unique IPs by getting all keys with the prefix and counting them
201 + uniqueIPs, err := RedisClient.Keys(c, RedisKey+"*").Result()
202 + if err != nil {
203 + c.JSON(500, gin.H{"error": "Internal server error"})
204 + return
205 + }
206 + uniqueIPCount := int64(len(uniqueIPs))
207 +
208 RedisClient.Expire(c, key, RedisKeyTtl)
209 message, _ := json.Marshal(IpMessage{Ip: ip})
210
...
259 return
260 }
261
262 - c.JSON(200, gin.H{"count": count, "text": ResponseString + "hi", "info": ipInfo, "info2": ipInfo2})
262 + c.JSON(200, gin.H{"count": count, "unique_ips": uniqueIPCount, "text": ResponseString + "hi", "info": ipInfo, "info2": ipInfo2})
263 }
264
265 func main() {
⏺ Bash(mirrord exec -f .mirrord/mirrord.json -- go run ip-visit-counter/main.go)
⎿ Running in the background (down arrow to manage)
⏺ BashOutput(Reading shell output)
⎿ (No content)
⏺ Bash(sleep 3)
⎿ (No content)
⏺ BashOutput(Reading shell output)
⎿ (No content)
⏺ Bash(curl -H "X-PG-Tenant: Aviram" playground.metalbear.dev/count)
⎿ {
"count": 1,
"info": {
… +13 lines (ctrl+r to expand)
⏺ Bash(curl -H "X-PG-Tenant: Aviram" playground.metalbear.dev/count)
⎿ {
"count": 2,
"info": {
… +17 lines (ctrl+r to expand)
⏺ Perfect! Let me test one more time to verify the count increases but unique_ips stays consistent for the same IP:
⏺ Bash(curl -H "X-PG-Tenant: Aviram" playground.metalbear.dev/count)
⎿ {
"count": 3,
"info": {
… +16 lines (ctrl+r to expand)
⏺ Excellent! The functionality is working correctly. Let me clean up and complete the testing:
⏺ Kill Bash(Kill shell: bash_2)
⎿ Shell bash_2 killed
⏺ ✅ Task completed successfully!
Modified the IP visit counter to return both the visit count and total unique IPs. The /count endpoint now returns:
- count: Individual IP visit count (increments each request)
- unique_ips: Total number of unique IPs stored in Redis
- All existing fields preserved
Test Results:
- First request: count: 2, unique_ips: 1
- Second request: count: 3, unique_ips: 1
The functionality works correctly - visit count increments per request while unique IP count reflects the total number of distinct IPs in Redis.
You can see here how Claude takes care of the full end-to-end cycle on its own. It searches through the codebase and makes the necessary changes to add a unique_ips field that counts the number of distinct IPs stored in Redis. After updating the code, Claude runs it with mirrord exec. This allows it to run the code locally while being able to interact directly with the cluster’s environment, meaning there’s no need to deploy the change to staging or spin up and configure a Redis instance on the local machine.
After that when Claude sends requests to the playground endpoint, mirrord sends that incoming traffic to the locally running process. The responses show both the incrementing count and the unique_ips field (which doesn’t change because every request is from the same IP). That proves the change is working as intended, because the local service is handling real traffic and talking to the actual Redis database in the cluster, without deploying the generated code.
Another important detail here is how mirrord uses traffic filtering. By setting the header X-PG-Tenant: Aviram, only requests tagged with that tenant value are sent to the local process. This ensures that one agent’s tests don’t interfere with other agents or developers working with the playground app. Each agent is effectively “sandboxed” to just its own session. The rest of the traffic keeps flowing normally to the deployed service, while every agent gets a realistic testing environment tied to its code changes.
The sooner your AI agents can test, the faster they can ship
If you look at the conversation history above, you’ll see that Claude tells us it tested the code change against the staging environment and it worked successfully. This is great because now we have the confidence that when we finally do deploy to staging, things will work on the first try.
But your AI agents won’t always get the code right on the first attempt. They often lack the context of your entire application, so it’s very likely that when they run integration tests on generated code, they’ll find that something breaks. The difference is that now the agent itself can read the error, fix the code, and try again without human supervision required.
Previously, this was impossible because integration testing meant committing, pushing, and waiting for CI/CD pipelines just to see if something broke. mirrord removes that bottleneck by letting the AI agent run those integration tests immediately and in parallel. Instead of waiting for one staging deployment after another, multiple agents can all test their changes concurrently against the same environment and iterate until the code works.
At that point, the only role left for you is a quick final verification through your normal CI/CD process before shipping. Everything else, from writing to testing to fixing, can be handled by your AI agents.
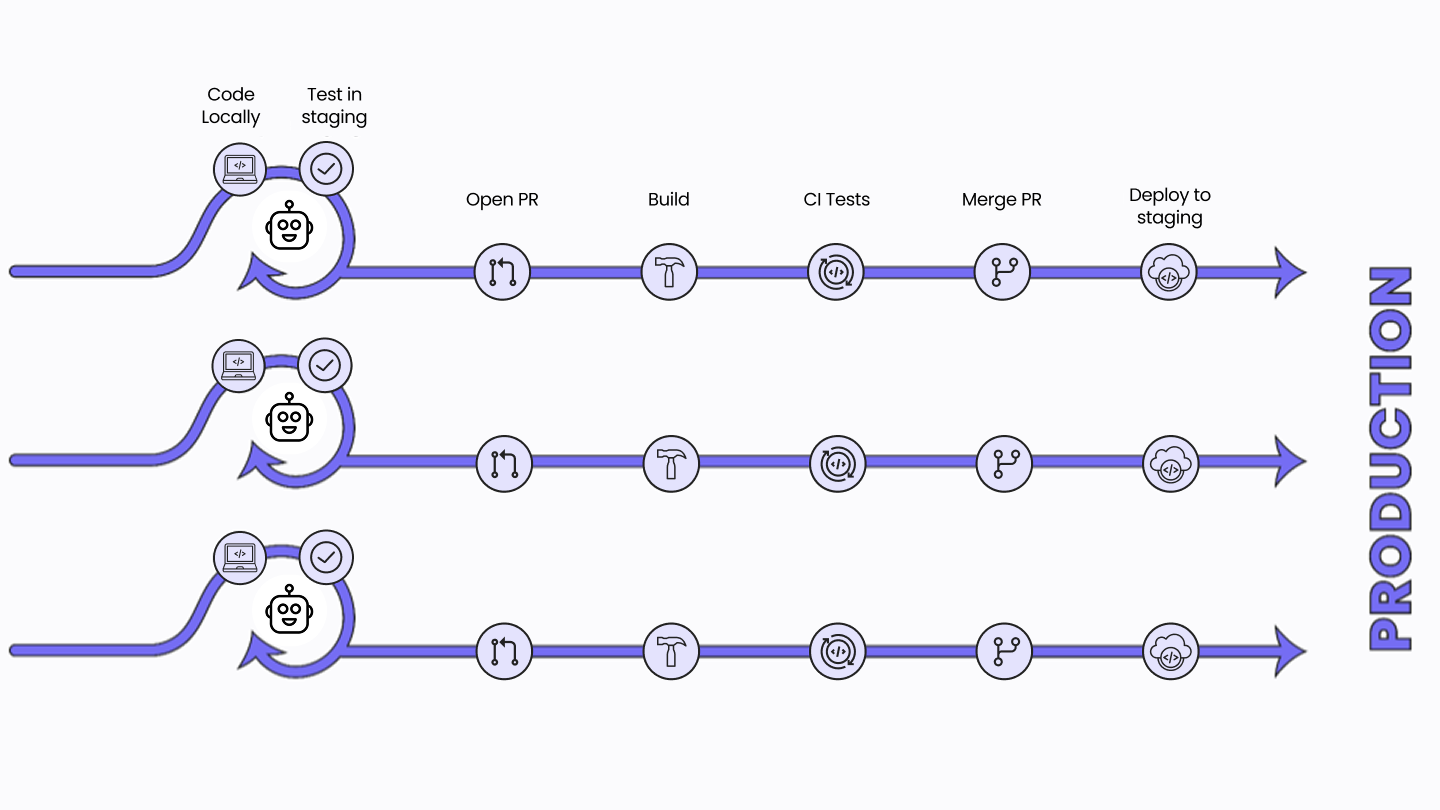
AI agents developing concurrently using mirrord
Equip your AI agents with mirrord and close the code development loop
The era of AI-assisted code generation has arrived, making coding faster and easier than ever. However, the true breakthrough in Agentic AI development will come when AI agents are equipped with the ability to test, validate, and iterate on their code autonomously. This is what will really unlock the full potential of Agentic AI development.
mirrord provides this missing link. It empowers your AI agents by allowing their locally generated code to run directly in the context of your Kubernetes cluster. This capability closes the loop on Agentic AI development, transforming a multi-stage, bottlenecked process into a continuous, high-fidelity feedback cycle. It enables AI agents to validate and ship code autonomously and with confidence.
Are you coding with Agentic AI? Close the development loop with mirrord today.

