Testing Is the New Bottleneck for AI-Driven Software Development
Today, AI coding agents are generating more code than ever. Yet despite this surge in output, many organizations aren’t shipping software proportionally faster, because while AI has dramatically accelerated writing code, it hasn’t improved testing and validation to the same degree. Verification has become the new bottleneck.
Why AI can’t verify its own work
Boris Cherny, the creator of Claude Code, put it plainly: “The most important thing to get great results out of Claude Code — give Claude a way to verify its work. If Claude has that feedback loop, it will 2–3x the quality of the final result.” How do you enable this verification when building cloud-native applications? In a microservices architecture running on Kubernetes, a service’s behavior depends on everything around it: other microservices, databases, queues, APIs, configuration, and secrets that only exist inside the cluster. Because of this, simply generating code is not enough, and the real challenge is getting that code to work correctly within the existing system.
Most AI coding agents can’t close that gap on their own. After generating code, engineers can review it and run limited unit tests locally, but eventually they have to wait for CI pipelines and staging deployments to see if it actually works. That process is slow for several reasons:
- It involves building and deploying container images, which can easily take 10–15 minutes each time you want to test
- Access to staging often requires approval and coordination with other teams who might also be using it
- Since staging is shared, there is the risk of new code breaking the environment for everyone, causing further delays
The result is a long, expensive feedback loop that hasn’t kept pace with how fast code is now being written.
How the industry is responding (and where it falls short)
The dominant response has been to give every developer or AI agent their own isolated environment. Vercel popularized the pattern for frontend apps where every PR gets its own preview deployment, isolated and ephemeral. GitLab extended the model to Kubernetes with Review Apps, spinning up a fresh namespace per merge request. The idea has since spread into the backend world, with many CI platforms and internal developer platforms offering some version of per-developer or per-PR ephemeral environments.
These environments aim to provide production-like testing while keeping changes fully isolated from other developers and services. Each developer or AI agent can deploy their code to its own sandbox environment and test it against the full system. In practice, however, this approach introduces its own challenges.
Provisioning and maintaining many isolated environments is expensive and operationally complex. Each one needs its own infrastructure, services, databases, queues, networking, and configuration mirroring the real system. And for large distributed applications, this replication becomes increasingly difficult. These environments also tend to drift from production over time and often lack realistic data, so code still gets tested in conditions that don’t reflect the real world. And you still have to build container images and deploy to them, which means the per-iteration time cost hasn’t fundamentally changed.
So while sandbox and ephemeral per-developer environments attempt to solve the testing bottleneck, they often replace one problem with another: maintenance overhead and higher infrastructure costs.
A better approach: remocal testing
The sandbox model assumes you need to replicate your environment for every developer or agent. But what if you could let multiple developers safely share a single environment that already mirrors production, like your existing staging cluster?
Instead of recreating the entire production environment, a developer runs the service they’re working on locally on their own machine, while connecting it to the real staging cluster. The code runs locally—no image builds, no deployments, nothing committed—but it behaves as if it were running inside the cluster. Incoming traffic from staging is mirrored to the local process, and outgoing calls from the local service reach the dependencies already in the cluster: databases, APIs, queues, and other microservices. This way you’re not testing against mocks or an out-of-date replica but against the actual system.
This approach of running locally but connected to a remote cluster is what we call “remocal” testing. Here’s what that workflow looks like end to end:
- The agent generates code for the service being modified.
- The developer or agent runs the service locally, connected to the staging cluster. No image build or deployment needed.
- The local service runs in the context of the cluster. It receives real incoming traffic mirrored from staging and communicates with real dependencies like databases, APIs, queues, and other microservices.
- Failures surface immediately. Wrong API call, missing config, unexpected response — these all show up in real time, not after a 15-minute CI run.
- The agent iterates with real feedback, adjusting the code based on observed system behavior rather than static analysis.
- Once the change works, it goes through the standard CI pipeline, but by that point it’s already been tested against the real cloud environment, so CI becomes a formality rather than a discovery phase.
The key advantage here is that the AI isn’t generating code blindly anymore. You’re able to provide it instant feedback from a production-like environment instead of having to wait until the end of the development cycle when you push to staging. This shorter feedback loop allows AI agents to iterate faster and produce code that actually works when it reaches staging or production.
mirrord: remocal testing for Kubernetes
mirrord lets developers run the AI-generated code locally on their machines while connecting it to an existing cluster by mirroring incoming and outgoing traffic, environment variables, and files between the cluster and the local process. The diagram below shows how this works:
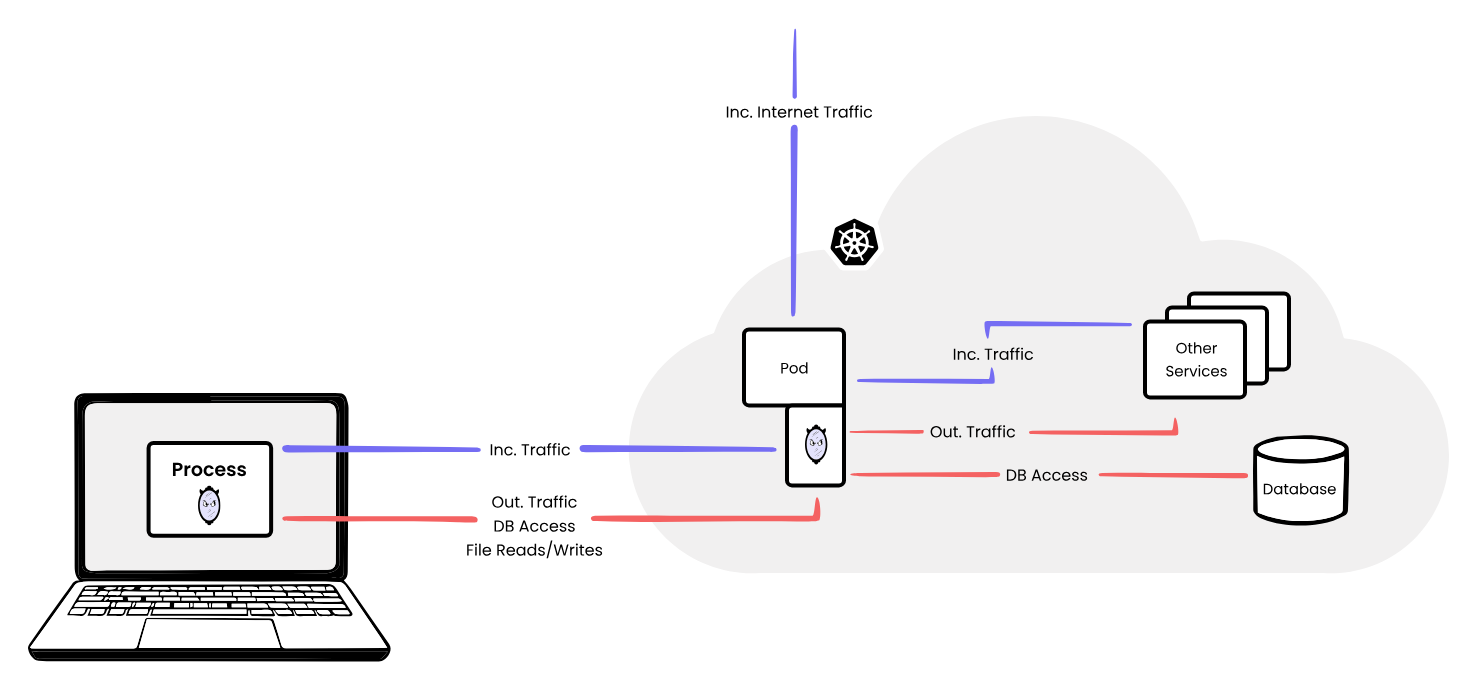
How mirrord works
mirrord comes with features like HTTP traffic filtering, queue splitting, and database branching, which let multiple developers safely use the same shared environment simultaneously without stepping on each other. Check out our docs to learn more.
AI agents can use mirrord before writing code, not just after
One underappreciated capability this enables is that AI agents can use mirrord to explore the environment before generating any code. The agent runs the existing service locally with mirrord connected to staging. It can then send a request directly to the staging endpoint, and because mirrord mirrors that traffic to the local process, the agent sees exactly how the service handles it: what the request looks like coming in, how the service calls its downstream dependencies, and what response it produces.
Rather than inferring how services are configured from static files, the agent gets to interact with the live system, observe real traffic and inspect things like environment variables and other cluster-specific configuration. This means the code it writes is based on how the system actually behaves, not how the agent assumes it behaves from reading source files alone.
The result is fewer iterations and code that’s more likely to be correct the first time.
AI coding tools + remocal testing = faster shipping
AI coding tools have changed how fast code can be written. But speed of generation doesn’t translate to speed of shipping if the verification step still takes hours per cycle. The teams that will get the most out of AI-assisted development aren’t necessarily the ones with the most powerful models. They’re the ones who’ve closed the feedback loop.

